
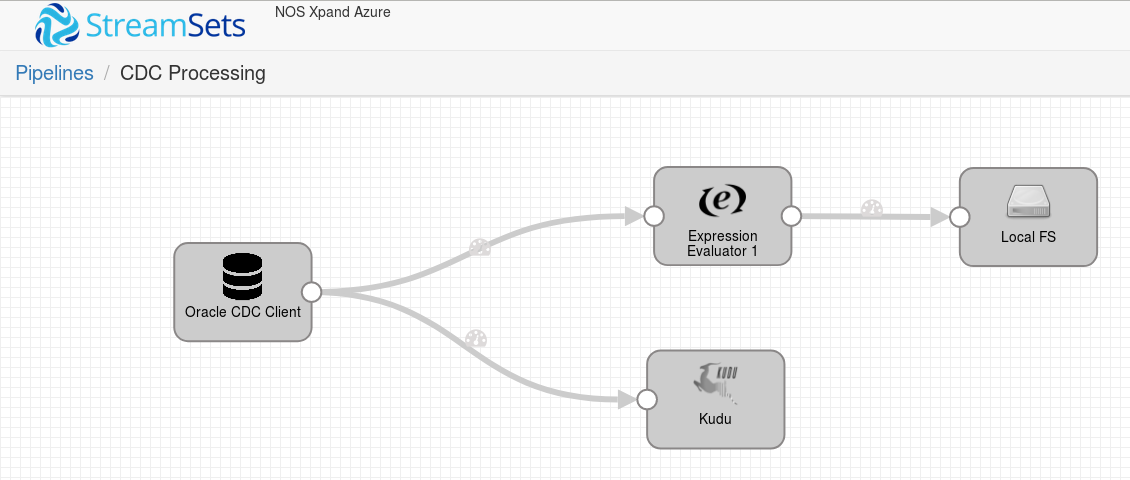
Processing Oracle CDC with StreamSets
This post presents a step-by-step guide on how to process change data capture (CDC) events with StreamSets, using it’s Oracle CDC Client and delivering to CRUD and non-CRUD destinations.
Oracle CDC Client processes CDC information provided by the Oracle LogMiner, which is a part of Oracle Databases and enables applications to query online and archived redo log files containing the history of activity on a database. You can use this origin to perform a real-time database replication, by simply using CRUD-enabled destinations such as Kudu. If you need to propagate the changes to a non-CRUD destination for further processing, an Expression Evaluator processor is required, as we will soon see.
Prerequisites
Before proceeding with the tutorial, you must ensure the following requirements are met:
1 - The Oracle’s JDBC Driver is installed using the Package Manager.
2 - The Oracle’s LogMiner is enabled. Check it by executing the query below as a DBA user:
SELECT log_mode FROM v$database;
The configured LOG_MODE should be ARCHIVELOG.
3 - The Supplemental logging is enabled. Supplemental logging can be of three types: minimum for the database, identification key and full. These can be set on a table or a database level. The easiest way is to enable the logging for the database, which can be checked with:
SELECT supplemental_log_data_min, supplemental_log_data_pk, supplemental_log_data_all FROM v$database;
| SUPPLEMENTAL_LOG_DATA_MIN | SUPPLEMENTAL_LOG_DATA_PK | SUPPLEMENTAL_LOG_DATA_ALL |
|---|---|---|
| YES | YES | YES |
The minimum database logging should be enabled, but you can choose between enabling the identification key or full logging. Depending on the enabled logging level, the generated by the origin records will contain the following information for each operation:
| Oplog Operation | Identification/Primary Key Logging Only | Full Supplemental Logging |
|---|---|---|
| INSERT | All fields that contain data, ignoring fields with null values. | All fields. |
| UPDATE | Primary key field and fields with updated values. | All fields. |
| SELECT_FOR_ UPDATE | Primary key field and fields with updated values. | All fields. |
| DELETE | Primary key field. | All fields. |
4 - A user account with the required privileges is created. For standard Oracle 12c databases, execute the following statements as a DBA user:
CREATE USER streamsets IDENTIFIED BY streamsets123456;
GRANT create session, alter session, select any dictionary, logmining, execute_catalog_role TO streamsets;
GRANT select on some.clients TO streamsets;
Note that we also allowed our streamsets user to perform select operations on our source clients table.
Oracle CDC Client Origin
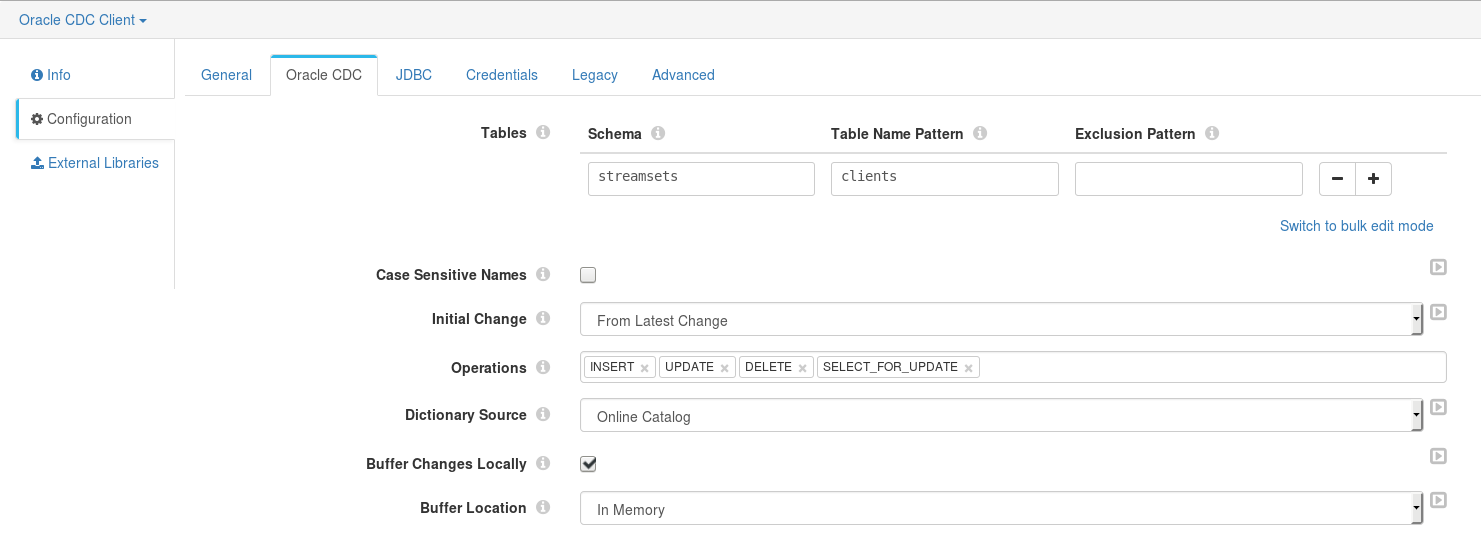
In Oracle CDC configuration tab shown above we need to specify the following parameters:
1 - Source table Schemaand Table Name Pattern (with a SQL-like syntax).
2 - Starting processing point with the Initial Change parameter. It has three possible values:
- From the latest change - Process all changes that occur after you start the pipeline.
- From a specified datetime - Process all changes that occurred at the specified datetime and later.
- From a specified Oracle’s system change number (SCN) - Process all changes that occurred in the specified SCN and later.
3 - The list of operations that should be captured as records in Operation parameter.
Then, in JDBC tab we provide the JDBC connection string and check the Use Credentials checkbox.
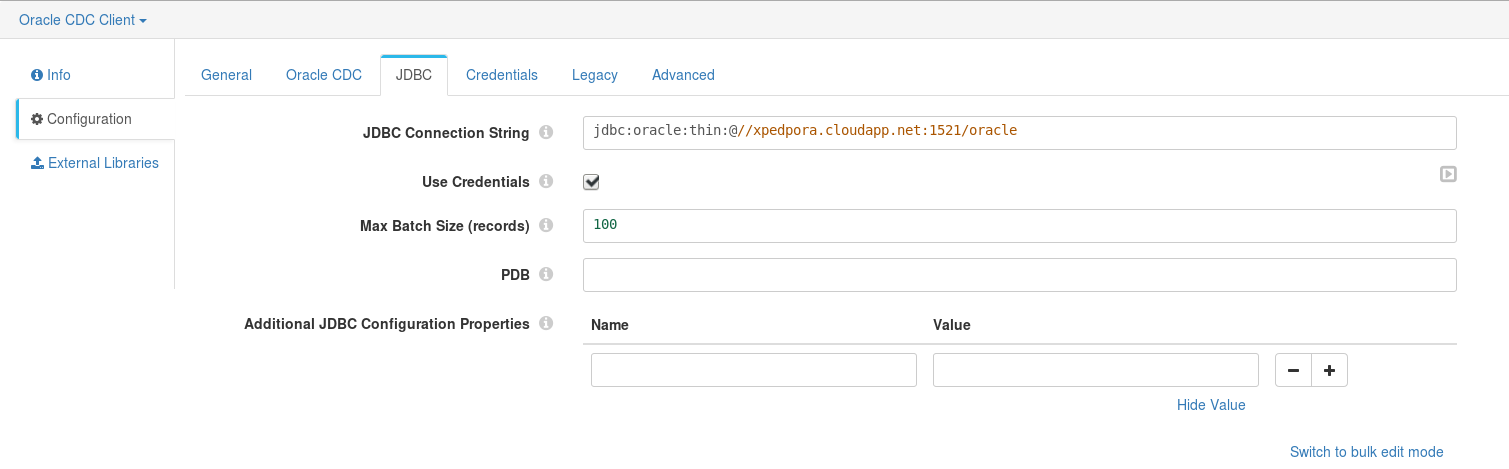
Finally, in Credentials tab we provide the connection username and password. The user to use is the one we previously created with the required grants.

CRUD-enabled Destination
StreamSets offers a set of CRUD-enabled Destinations to deliver CDC records to. These destinations take into consideration the CDC related attributes added by the Oracle CDC Client origin, contained within the record’s Header, for example the oracle.cdc.operation. This attribute informs the destination system how to process each record and since all the CRUD-enabled destinations support INSERT, UPDATE and DELETE operations, StreamSets can instantly replicate our source relational database table by applying the same operations on those destinations.
All the destinations listed below support this capability:
In our demostration pipeline we will use the Kudu destination.
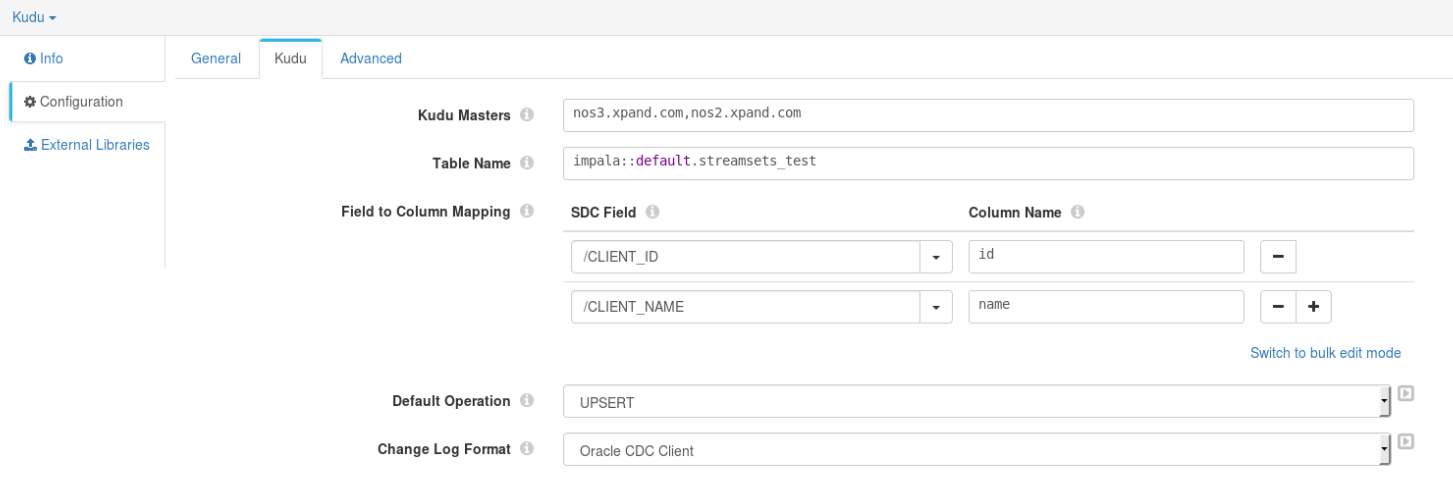
Kudu Destination
Kudu destination can be easily configured to process CDC records, by specifying the following properties:
Kudu Masterscomma-separated list- Target Kudu
Table Name Field to Column Mapping(Note: Oracle CDC Client origin puts all the source table columns in uppercase)Default Operation- only used when processing a record that do not containsdc.operation.typeattribute in its HeaderChange Log Format- containing the CDC record origin
Non-CRUD Destinations
We may also need to deliver the CDC records to a non-CRUD destination, any destination not listed above, however an additional Expression Evaluator processor is required.
CDC related information is only contained in record Header’s attributes, which means that if we directly connect a non-CRUD destination to the Oracle CDC Client, the written records (in JSON format) will only contain the source table columns and values:
{
"CLIENT_ID": 10,
"CLIENT_NAME": "Andriy"
}
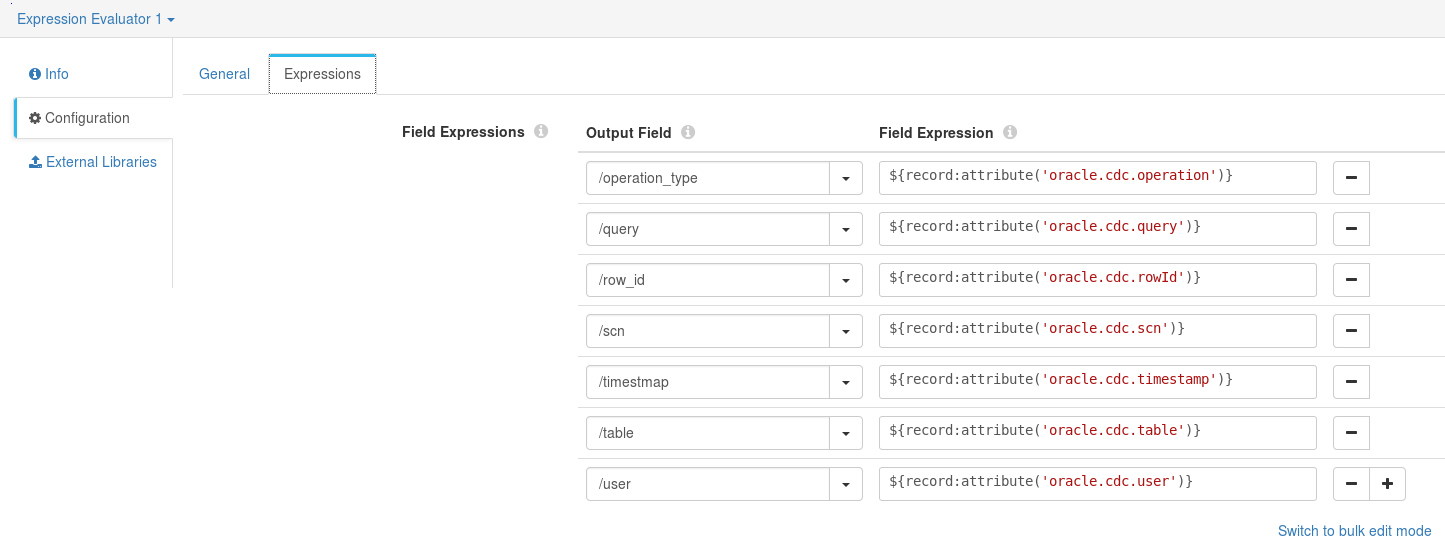
Expression Evaluator allows us to extract the CDC information from record Header’s attributes and include it in the record Fields. All the attributes provided by the Oracle CDC Client and how we can extract them are listed in the Field Expressions parameter below:
Using the StreamSets’ Preview feature, we can check the result of the configured mappings:
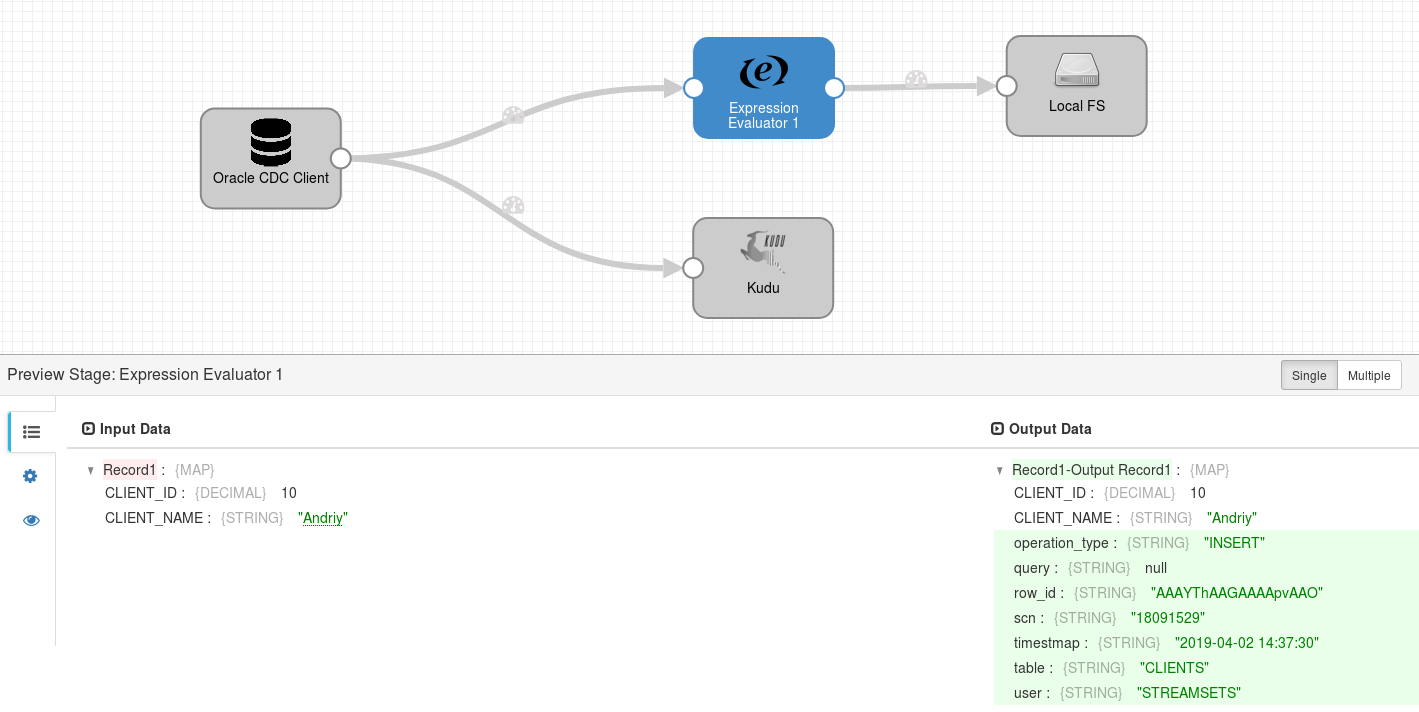
Now the resulting records are enriched with CDC information and are ready to be delivered to a non-CRUD destination for further processing:
{
"CLIENT_ID": 10,
"CLIENT_NAME": "Andriy",
"operation_type": "INSERT",
"query": null,
"row_id": "AAAYThAAGAAAApvAAO",
"scn": "18091529",
"timestmap": "2019-04-02 14:37:30",
"table": "CLIENTS",
"user": "STREAMSETS"
}
Pipeline Execution
Origins Overwiew page from StreamSets documentation clearly points that the Oracle CDC Client origin is only available in Standalone pipelines, which means that the pipeline-level parameter Execution Mode should be set to Standalone.
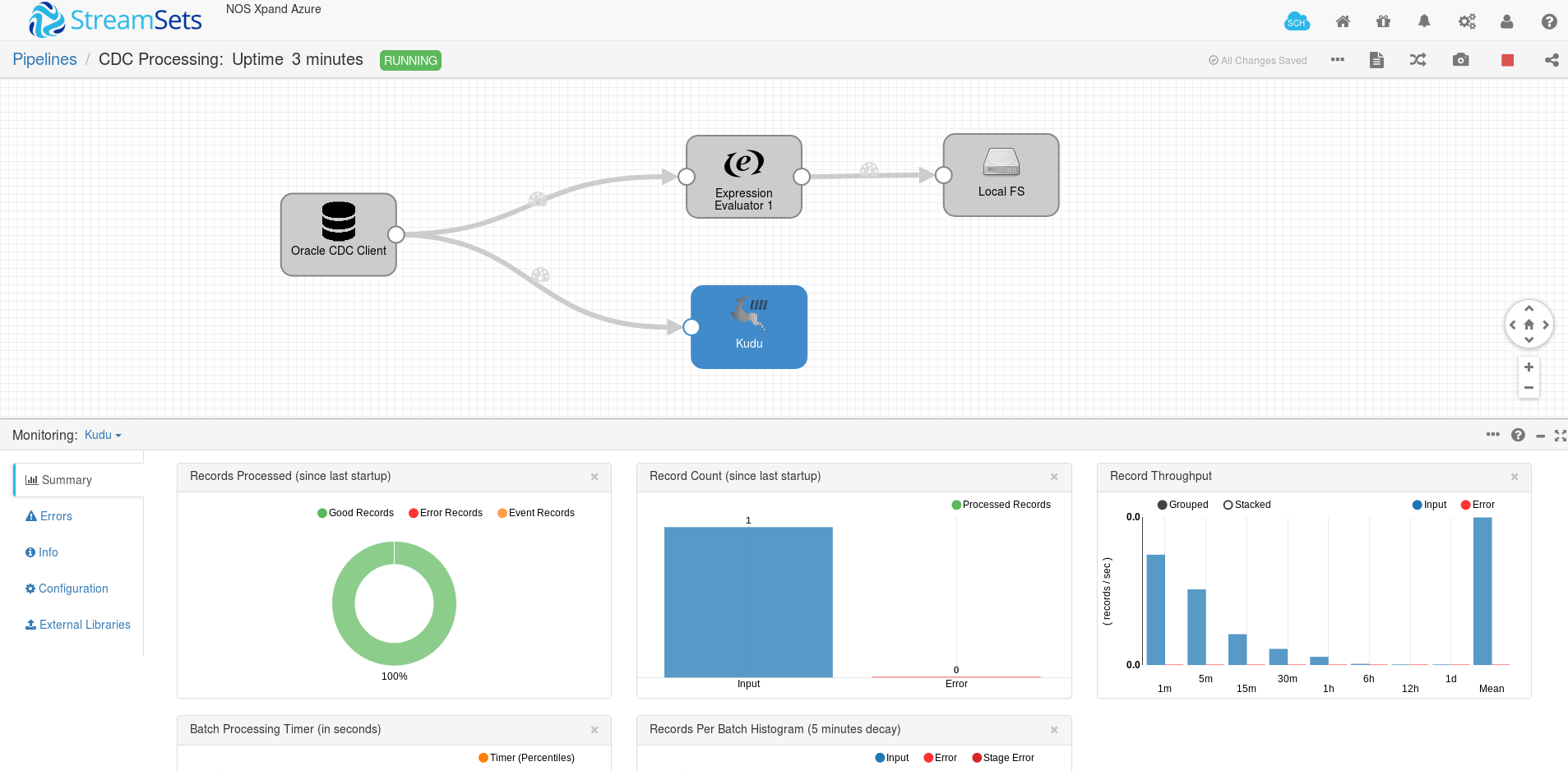
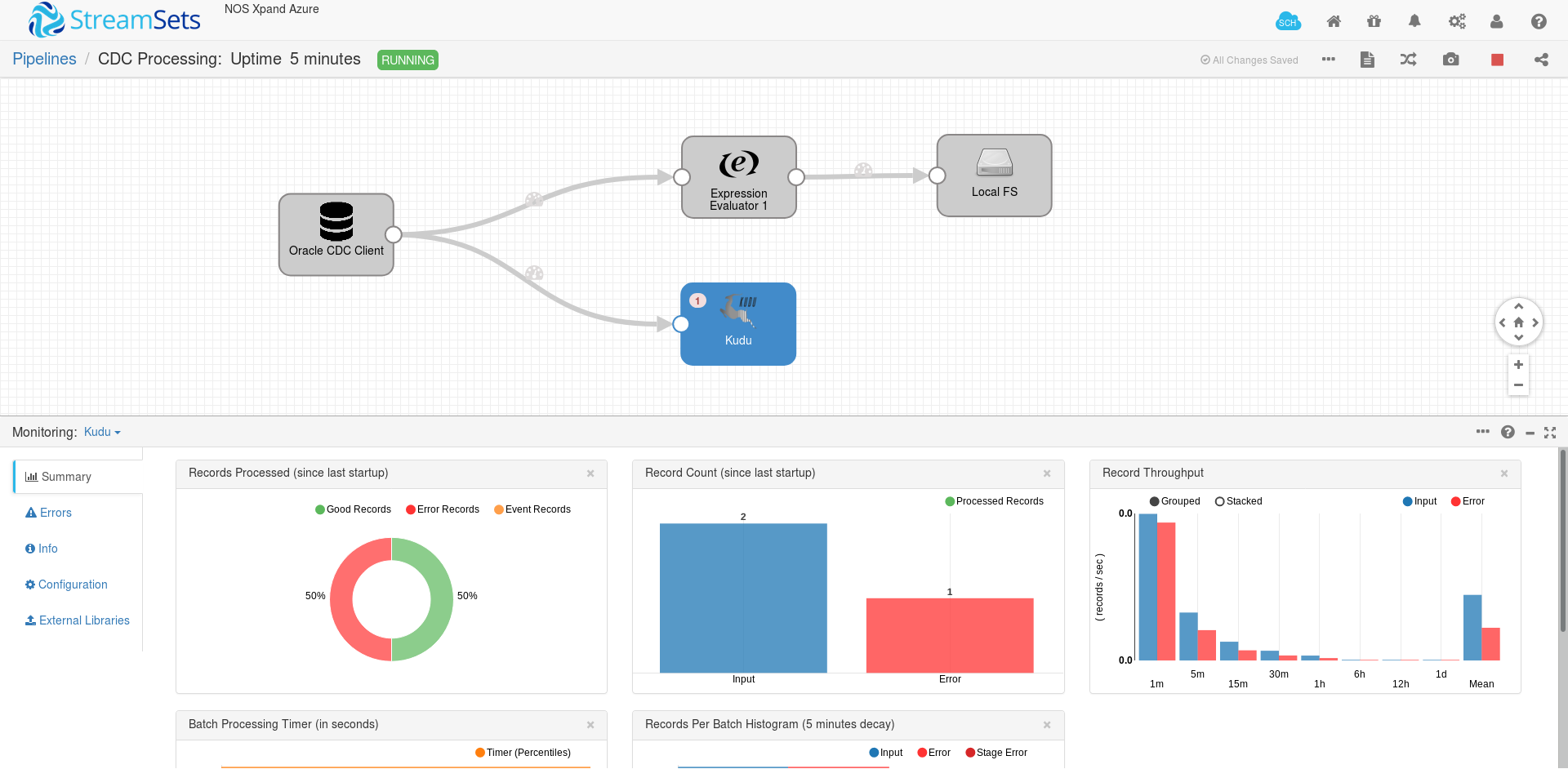
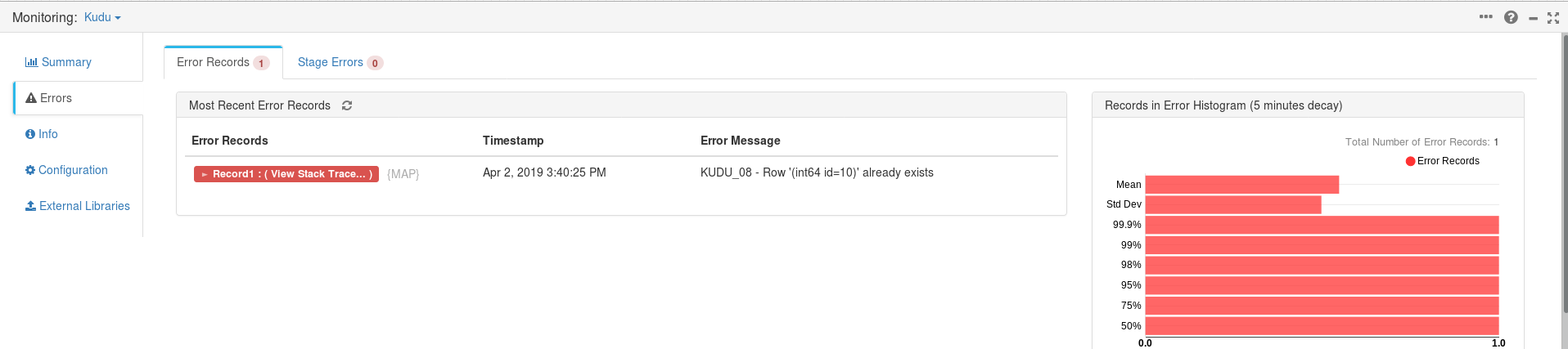
Finally, we can start the pipeline and monitor its execution with the provided metrics. If a record is not successfully delivered to a destination we can check its failure reason. For example, the presented below error appeared after the Primary Key constraint violation for a target Kudu table.
Leave a comment