
How Kafka Is so Performant If It Writes to Disk?
A Kafka Broker is nothing more, nothing less, than a JVM process that runs on a machine that serves data store/fetch requests from clients, i.e Producers and Consumers.
The data itself is stored in specific directories configured with log.dirs, typically a list of disk mount points of that Broker. You have probably heard before that disk IO is slow, but if Kafka uses disk to store log segments, how is it so performant? Let’s analyze this.
This post covers how traditional data transfer works, what is a Zero Copy optimization and how Kafka benefits from it when combined with the Page Cache.
Traditional Data Transfer
To read a file from disk and send it over the network a traditional data transfer would require four context switches between user mode and kernel mode, making the data being copied four times.
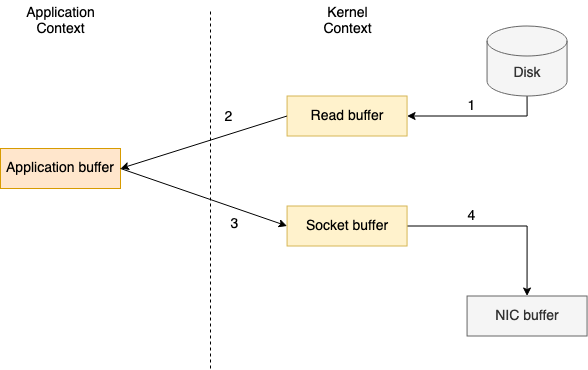
The transfer process consists in four steps below:
- The
File.read(...)call makes the context switch from user mode to kernel mode and the data copy is perfomed by the direct memory access (DMA) engine, which reads the file content and stores it into a kernel address space buffer (read buffer); - Data is copied from kernel space buffer into the user buffer, making the
File.read(...)call return and the context to switch back to user mode; - The
Socket.send(...)call makes the context switch to kernel mode and the third data copy is performed from user buffer to kernel buffer again; - The
Socket.send(...)call returns and makes the last context switch to user mode. A fourth copy of the data is performed by the DMA engine, passing it from kernel buffer (socket buffer) to the network interface controller (NIC) buffer to be sent over the network.
If requested data is larger in size than the kernel buffer size, there will be even more copies between kernel and user spaces. Zero copy optimization reduces these redundant data copies.
Zero Copy Data Transfer
A zero copy optimization consists on removing the second and third data copies, making the data being transferred directly from the read buffer to the socket buffer.
In UNIX and various flavors of Linux this optimized data transfer is handled by sendfile() system call, which copies data between two file descriptors.
A JVM based application should use FileChannel’s transferTo() method, which under the hood invokes the system call in case zero copy is supported by the underlying operating system.
Context switches are reduced from four to two, during a FileChannel.transferTo(...) call and its return. Regarding the data copies, those may be reduced from four to two or tree, depending if the underlying NIC supports gather operations (feature available on Linux kernels 2.4 and later).
When gather operations is not supported, there is a need to do a copy from the read buffer to the socket buffer. However, since both reside in kernel, it is handled by the DMA engine.
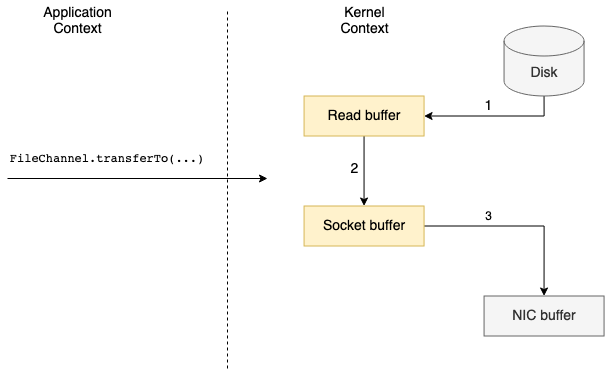
In case gather operations is supported by the NIC, only descriptors with the information about the location and length of the data are written to the socket buffer. The data is passed directly from the read buffer to the NIC.
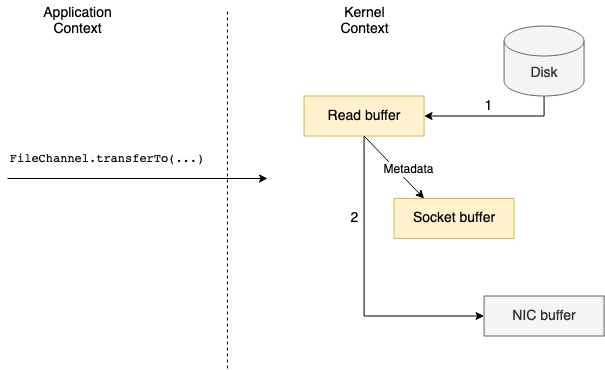
Kafka’s Data Transfer
Kafka heavily uses operating system’s Page Cache to store recently-used data, being this the reason why it is important to have a considerable amount of memory (RAM) on Broker’s machine.
Page Cache lays within unused portions of the RAM and is used to store pages of data that were recently read from or written to disk.
Another important design aspect of Kafka is that the Producer, Broker and Consumer share a standardized binary message format. This means the data is transfered from a Producer to a Broker and is stored as-is, without any modification. The same binary data is then sent to the Consumers when requested.
When a Broker receives data from a Producer, it is immediately written to a persistent log on the filesystem, however this does not mean it will be flushed to disk. The data will be transferred into the kernel’s page cache and it will be up to the operating system to decide when the flush should happen, i.e depending on the configured vm.dirty_ratio, vm.dirty_background_ratio and vm.swappiness kernel parameters.
Now that we covered what a zero copy optimization is, Kafka’s standardized binary message format and its design on using the page cache, we can fully understand the excerpts below taken from Kafka’s documentation:
We expect a common use case to be multiple consumers on a topic. Using the zero-copy optimization above, data is copied into pagecache exactly once and reused on each consumption instead of being stored in memory and copied out to user-space every time it is read. This allows messages to be consumed at a rate that approaches the limit of the network connection.
This combination of pagecache and sendfile means that on a Kafka cluster where the consumers are mostly caught up you will see no read activity on the disks whatsoever as they will be serving data entirely from cache.
In other words, if we have 3 Consumers (with different group.id) requesting data for a specific topic, on the Broker the data will be copied from disk into the page cache only once and will be sent over the network to each Consumer. If they were recently produced messages for that topic, the disk read will not be required, since “warm” data will still be present on page cache. This is possible because the writes and reads for a topic partition are only handled by the partiton “leader” and the producer records are written to an append-only segment file. This means that frequent read and write operations on the same topic will be fast because the segment file(s) will be on the page cache.
SSL and Zero Copy
Since SSL allows to encrypt data in flight, we no longer send over wire the same data that is stored on the Broker. This means that when SSL is enabled, zero copy optimization is lost, since the Broker needs to decrypt and encrypt the data. There is no reference to this on Kafka’s documentation, but it was confirmed by Kafka contributors in this tweet. It is expected to have some performance overhead when SSL is enabled.
Resources
Efficient data transfer through Zero Copy
Zero Copy I: User-Mode Perspective by Linux Journal
Understanding vm.swappiness – Linux Hint
Leave a comment