
Implement Custom Spark Evaluators in StreamSets
This post presents a step-by-step guide on how to implement custom Spark Evaluators in StreamSets.
The Spark Evaluator performs custom processing within a pipeline based on a Spark application. You can only use the Spark Evaluator processor in cluster pipelines that process data from a Kafka or MapR cluster in cluster streaming mode. For example, a pipeline in Cluster Yarn Streaming execution mode with Kafka Consumer origin is processed by the Data Collector in a spawned Spark Streaming application. Such pipeline can benefit from Spark Evaluators to transform the records with custom-developed code, allowing us to implement much complex transformation logic not possible using the provided Processors.
Implementing the SparkTransformer
The main class of your Spark Evaluator must extend the SparkTransformer abstract class and implement its init, transform and destroy methods.
The init method is optional and is called once when the pipeline starts to read arguments that you configure in the Spark Evaluator processor. You can use this method to create any connections to external systems.
void init(JavaSparkContext context, List<String> parameters)
// OR
void init(SparkSession session, List<String> parameters)
The transform method is required and is called for each batch of records that the pipeline processes. The Spark Evaluator processor passes the batch data with RDD of Records parameter.
TransformResult transform(JavaRDD<Record> recordRDD)
The destroy method is also optional and should be used to close any connections to external systems initialized in init method, since it is called when the pipeline stops.
void destroy()
Example
Before implementing your custom Spark Evaluator, you’ll need to include the required dependency in your project:
<dependency>
<groupId>com.streamsets</groupId>
<artifactId>streamsets-datacollector-spark-api</artifactId>
<version>3.7.2</version>
<scope>provided</scope>
</dependency>
The code snippet below represents a working example of a custom Spark processor, implemented by extending the SparkTransformer abstract class and overriding the init and transform methods.
package com.xpandit.bdu
import java.util.regex.Pattern
import com.streamsets.pipeline.api.Field.Type
import com.streamsets.pipeline.api.{Field, Record}
import com.streamsets.pipeline.spark.api.{SparkTransformer, TransformResult}
import com.xpandit.bdu.commons.core.Loggable
import org.apache.spark.SparkContext
import org.apache.spark.api.java.{JavaPairRDD, JavaRDD, JavaSparkContext}
import scala.collection.JavaConverters._
class ValidateFieldTransformer extends SparkTransformer with Serializable with Loggable {
var sparkContext: SparkContext = _
var emptyRDD: JavaRDD[(Record, String)] = _
var fieldRegexMap: Map[String, Pattern] = _
override def init(javaSparkContext: JavaSparkContext, parameters: java.util.List[String]): Unit = {
sparkContext = javaSparkContext.sc
fieldRegexMap = parameters.asScala.map { param =>
val sepIndex = param.indexOf(' ')
val fieldName = param.substring(0, sepIndex)
val regex = param.substring(sepIndex + 1)
INFO(s"Got: '$fieldName' -> '$regex'")
fieldName -> Pattern.compile(regex, Pattern.CASE_INSENSITIVE)
}.toMap
}
override def transform(javaRDD: JavaRDD[Record]): TransformResult = {
val rdd = javaRDD.rdd
val errors = sparkContext.emptyRDD[(Record, String)]
val fieldRegexMapLocal = fieldRegexMap // Using directly 'fieldRegexMap' results in this class instance serialization
val transformedRDD = rdd.map { record =>
val rootField = record.get.getValueAsMap
fieldRegexMapLocal.foreach { case (fieldName, pattern) =>
if(rootField.containsKey(fieldName) && rootField.get(fieldName).getType == Type.STRING){
val isValid = pattern.matcher(rootField.get(fieldName).getValueAsString).matches()
rootField.put("valid" + fieldName.capitalize, Field.create(isValid))
}
}
record
}
new TransformResult(transformedRDD.toJavaRDD(), new JavaPairRDD[Record, String](errors))
}
}
This processor receives through the init method parameters strings containing a field name together with the RegEx that should be validated, which will be provided through the Data Collector UI as we will soon see. E.g. email ^[A-Za-z0-9._%+-]+@[A-Za-z0-9.-]+\.[A-Za-z]{2,6}$
The init method uses the received parameters to populate the Map[String, Pattern] collection containing a compiled representation of a regular expression for every field. Also init saves the instance of SparkContext contained within the received JavaSparkContext object. Saving its instance allows us to create empty RDDs in the transform method.
The transform method receives a JavaRDD[Record] parameter, where JavaRDD is just a wrapper around an RDD, used in Spark’s Java API. The Record contained in it is the internal class StreamSets uses to represent each of the processed records.
A Record contains a Header with attributes and a root Field containing the record’s data. Header’s attributes are represented by a key/value map collection and contain a set of origin or user defined entries. The Field is a data structure construct consisting of a type/value pair. It supports basic types (i.e. numbers, strings, dates) as well as structure oriented types (i.e. Maps and Lists).
Depending on the configured origin and its data format, the data is represented differently within the Record’s root Field. For example, with a Kafka Consumer and JSON data format as origin, the processed JSON is represented in StreamSets as follows:
{
"email": "testing@gmail.com",
"digits" : "123ups456"
}
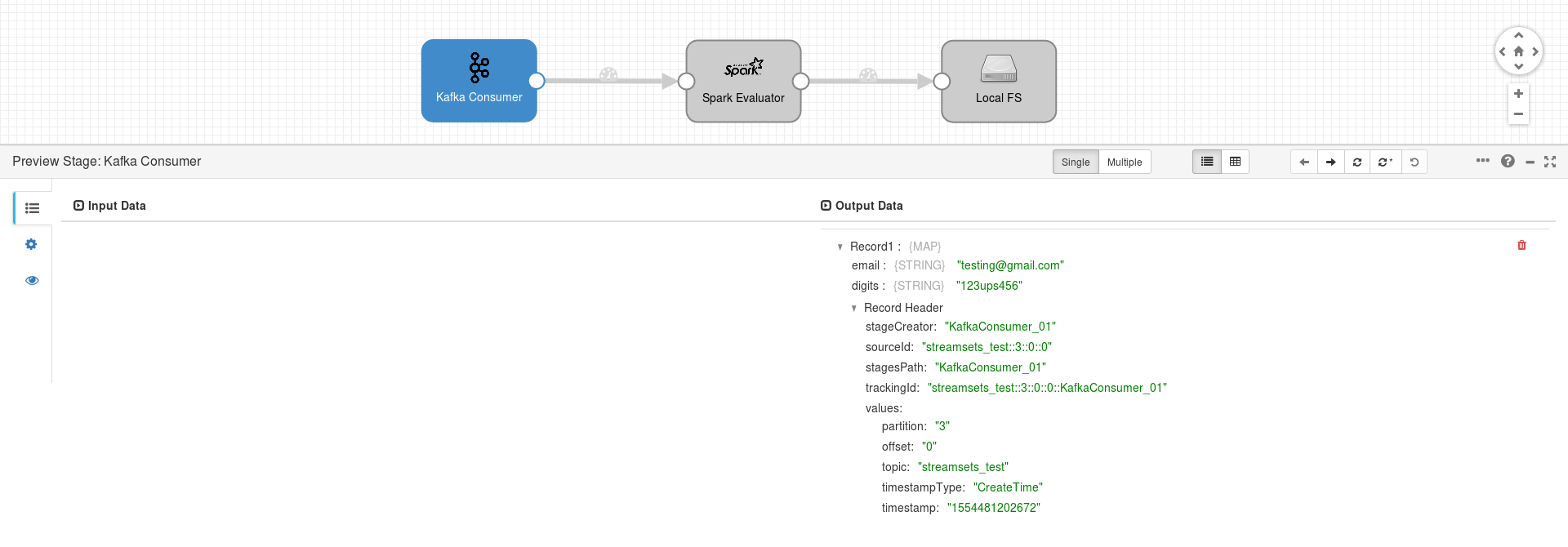
In transform implementation all the processing logic happens inside the rdd.map Spark transformation. For each record you get its root Field and validate the entries contained in it with the stored regular expression Patterns. For every checked field we add another one containing a boolean with the RegEx matching result:
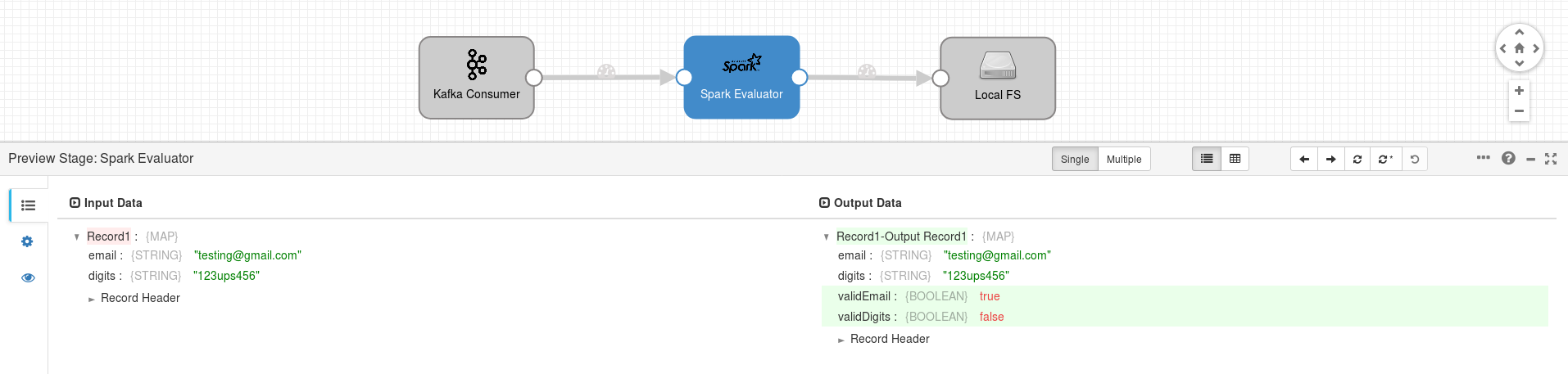
Notice that the SparkContext instance is used to create an empty RDD for errors, which together with the transformed RDD are passed as parameter to create an instance of TransformResult, returned by the transform method. The transformed RDD will be then passed to the next pipeline stage and the error RDD processed according to the Spark Evaluator processor configuration.
Packaging the SparkTransformer implementation
Your custom Spark Evaluator implementation should be bundled in a JAR package.
If you use Maven to build your project, by default the dependant JARs are not packaged. In case you use any external libraries in your custom Spark Evaluator, you will need to create a fat/uber JAR with Maven Assembly Plugin.
An important detail not mentioned anywhere in StreamSets documentation and examples is that the included streamsets-datacollector-spark-api dependency should have provided scope, since it is already included by the Data Collector, otherwise the pipeline will crash in runtime with:
java.lang.RuntimeException: Validate errors when loading services: [Service interface com.streamsets.pipeline.api.service.dataformats.DataFormatParserService have multiple implementations., Service interface com.streamsets.pipeline.api.service.dataformats.DataFormatGeneratorService have multiple implementations., Service interface com.streamsets.pipeline.api.service.dataformats.DataFormatGeneratorService have multiple implementations., Service interface com.streamsets.pipeline.api.service.dataformats.DataFormatParserService have multiple implementations.]
at com.streamsets.datacollector.stagelibrary.ClassLoaderStageLibraryTask.validateServices(ClassLoaderStageLibraryTask.java:683)
at com.streamsets.datacollector.stagelibrary.ClassLoaderStageLibraryTask.initTask(ClassLoaderStageLibraryTask.java:295)
at com.streamsets.datacollector.task.AbstractTask.init(AbstractTask.java:62)
at com.streamsets.datacollector.task.CompositeTask.initTask(CompositeTask.java:44)
at com.streamsets.datacollector.task.AbstractTask.init(AbstractTask.java:62)
at com.streamsets.datacollector.task.TaskWrapper.init(TaskWrapper.java:40)
at com.streamsets.datacollector.main.Main.lambda$doMain$1(Main.java:118)
at java.security.AccessController.doPrivileged(Native Method)
at com.streamsets.datacollector.security.SecurityUtil.doAs(SecurityUtil.java:92)
at com.streamsets.datacollector.main.Main.doMain(Main.java:153)
at com.streamsets.datacollector.main.DataCollectorMain.main(DataCollectorMain.java:55)
at sun.reflect.NativeMethodAccessorImpl.invoke0(Native Method)
at sun.reflect.NativeMethodAccessorImpl.invoke(NativeMethodAccessorImpl.java:62)
at sun.reflect.DelegatingMethodAccessorImpl.invoke(DelegatingMethodAccessorImpl.java:43)
at java.lang.reflect.Method.invoke(Method.java:498)
at com.streamsets.pipeline.BootstrapMain.main(BootstrapMain.java:307)
To check that the fat JAR was generated correctly, you can list out the content with:
jar -tf streamsets-spark-transformer-1.0.jar
Configuring the Spark Evaluator
After packaging the processor implementation in a JAR, you can configure a pipeline using your custom Spark Evaluator. This tutorial focuses exclusively on Spark Evaluator, so the configuration of pipeline origin and destinations are out of our scope. The steps below contain instructions to configure a Spark Evaluator:
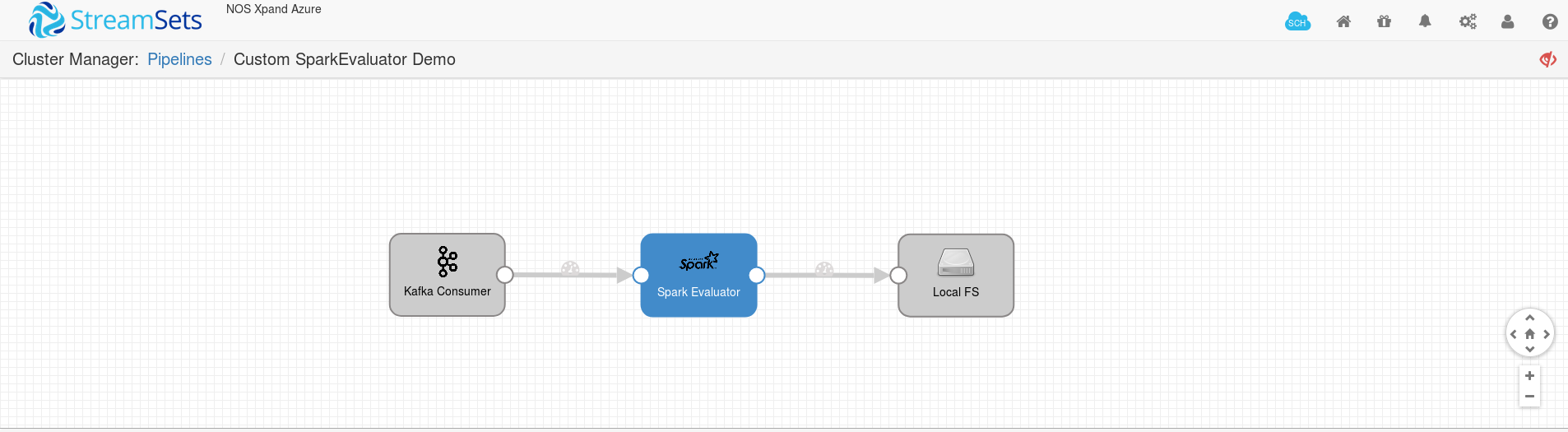
1 - Create a pipeline with Kafka Consumer as origin, Spark Evaluator as processor and any destination of your choice.
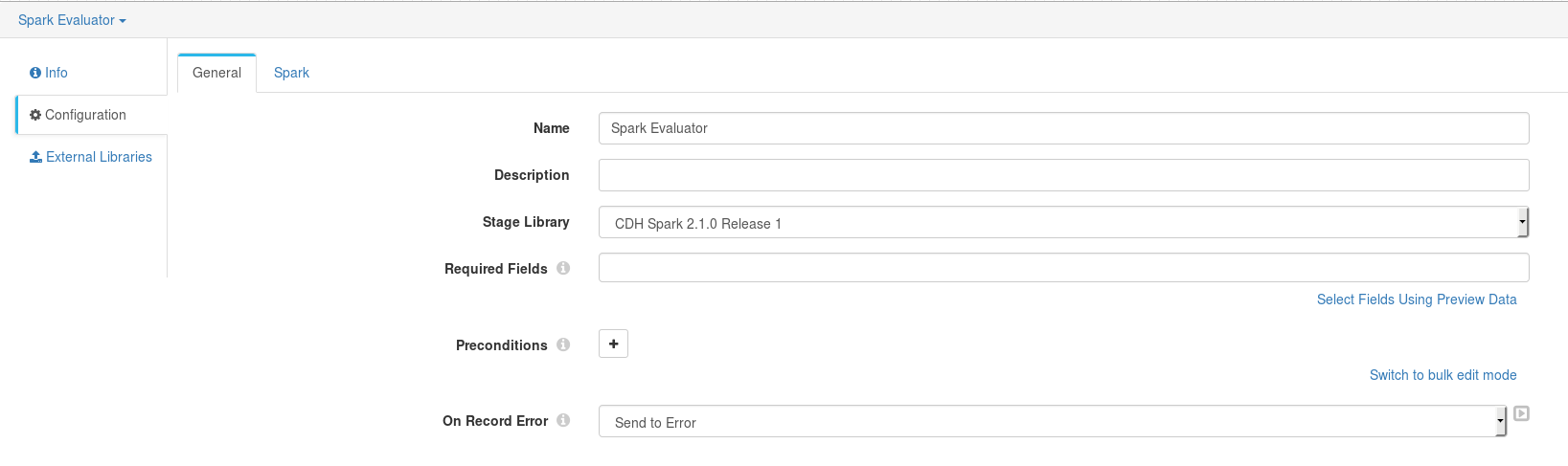
2 - Click on Spark Evaluator and in General tab choose the Stage Library compatible with our Cluster Yarn Streaming execution mode (an error pops-up if you choose a non-compatible library) and if possible which matches the Spark 2 version installed in our cluster.
3 - Add the transformer implementing JAR to the External Libraries.
Unfortunately, the tested 3.7.2 version of StreamSets has a known bug which does not allow to upload the library on Spark Evaluator’s configuration. Clicking on the upload icon simply has no effect.

The library can still be uploaded using the Package Manager, by choosing the same Stage Library and providing the implementation JAR, see Install External Libraries.
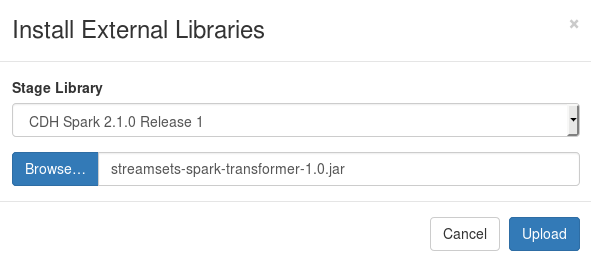
After uploading the JAR the Data Collector should be restarted. Another problem I noticed is that the restart is not performed by clicking on Restart Data Collector. The Data Collector instance stops and is not started, until you start it manually.
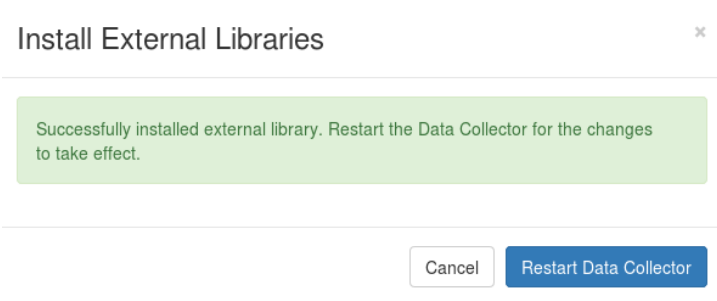
Removing a previously uploaded JAR also seems not possible because the checkbox seems not be working as well (ugh!), but uploading a JAR with the same name replaces the existing one.
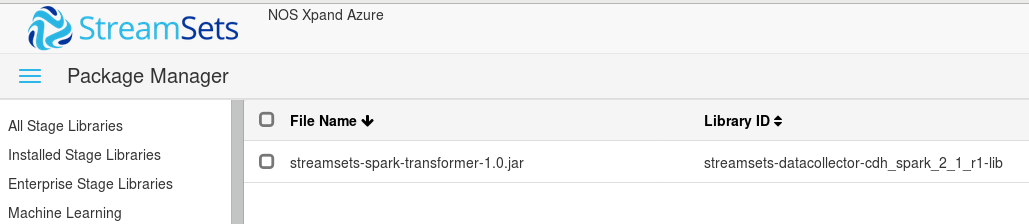
Additionally, it is also possible to directly replace the JAR in its directory. Removing the library also works as workaround, since it is correctly reflected in the UI.
[root@nos3 sdc-extras]# tree
.
└── streamsets-datacollector-cdh_spark_2_1_r1-lib
└── lib
└── streamsets-spark-transformer-1.0.jar
4 - Check that the External Library is available in Spark Evaluator configurations, if it is not, then you may’ve uploaded a JAR to a non-matching Spark Evaluator’s Stage Library.

5 - In Spark tab provide the package of the class implementing the Spark Transformer and the Init Method Arguments your class is expecting. Out tutorial implementation receives strings containing a field name together with the RegEx that should be validated.
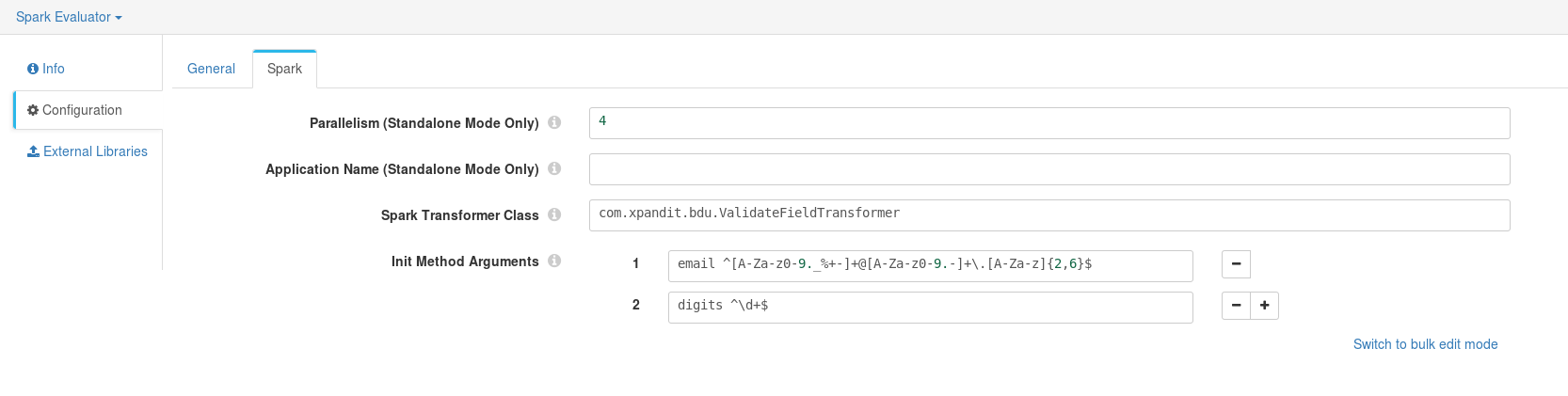
6 - Finally, you can validate if the Spark Evaluator works as expected by running the Preview feature. In the example below you can see highlighted in green the added Fields containing the RegEx validity.
Leave a comment