
Transactional Writes in Spark
Since Spark executes an application in a distributed fashion, it is impossible to atomically write the result of the job. For example, when you write a Dataframe, the result of the operation will be a directory with multiple files in it, one per Dataframe’s partition (e.g part-00001-...). These partition files are written by multiple Executors, as a result of their partial computation, but what if one of them fails?
To overcome this Spark has a concept of commit protocol, a mechanism that knows how to write partial results and deal with success or failure of a write operation.
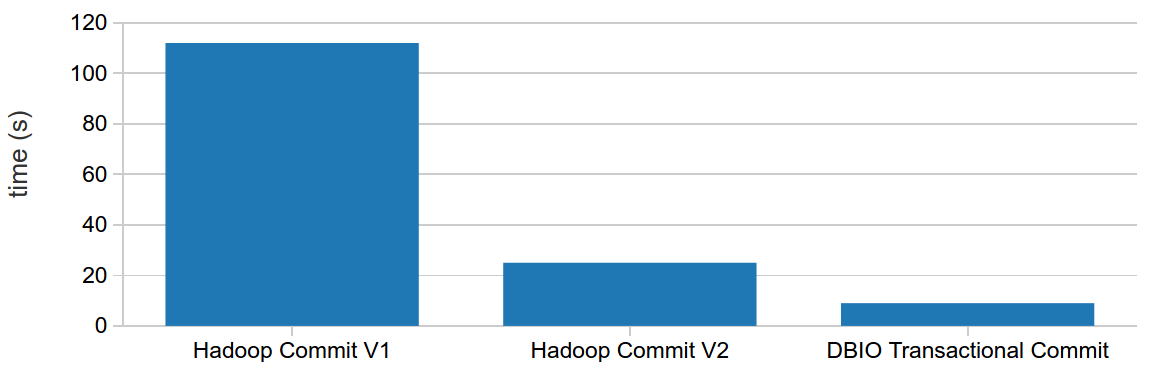
In this post I’ll cover three types of transactional write commit protocols and explain the differences between them. The protocols being addressed are Hadoop Commit V1, Hadoop Commit V2 and Databrick’s DBIO Transactional Commit.
Transactional Writes
In Spark the transactional write commit protocol can be configured with spark.sql.sources.commitProtocolClass, which by default points to the SQLHadoopMapReduceCommitProtocol implementing class, a subclass of HadoopMapReduceCommitProtocol.
There are two versions of this commit algorithm, configured as 1 or 2 on spark.hadoop.mapreduce.fileoutputcommitter.algorithm.version.
In version 1 Spark creates a temporary directory and writes all the staging output (task) files there. Then, at the end, when all tasks compete, Spark Driver moves those files from temporary directory to the final destination, deletes the temporary directory and creates the _SUCCESS file to mark the operation as successful. You can check more details of this process here.
The problem of version 1 is that for many output files, Driver may take a long time in the final step. Version 2 of commit protocol solves this slowness by writing directly the task result files to the final destination, speeding up the commit process. However, if the job is aborted it will leave behind partial task result files in the final destination.
Spark supports commit protocol version configuration since its 2.2.0 version, and at the time of this writing Spark’s latest 3.0.1 version has a default value for it depending on running environment (Hadoop version).

Transactional Writes on Databricks
As we previously saw, Spark’s default commit protocol version 1 should be used for safety (no partial results) and version 2 for performance. However, if we opt for data safety version 1 is not suitable for cloud native setups, e.g writing to Amazon S3, due to differences cloud object stores have from real filesystems, as explained in Spark’s cloud integration guide.
To solve the problem of left behind partial results on job failures and performance issues, Databricks implemented their own transactional write protocol called DBIO Transactional Commit.
You can check all the problems with Spark’s default commit protocol and the details behind Databrick’s custom implementation in Transactional I:O on Cloud Storage in Databricks talk by Eric Liang and Transactional Writes to Cloud Storage on Databricks blog post.
Let’s take a look with examples how transactional writes work on Databricks, implemented with the commit procotol below:

By writing the Dataframe to a directory, mount point of an Azure Storage container, the following files were created:
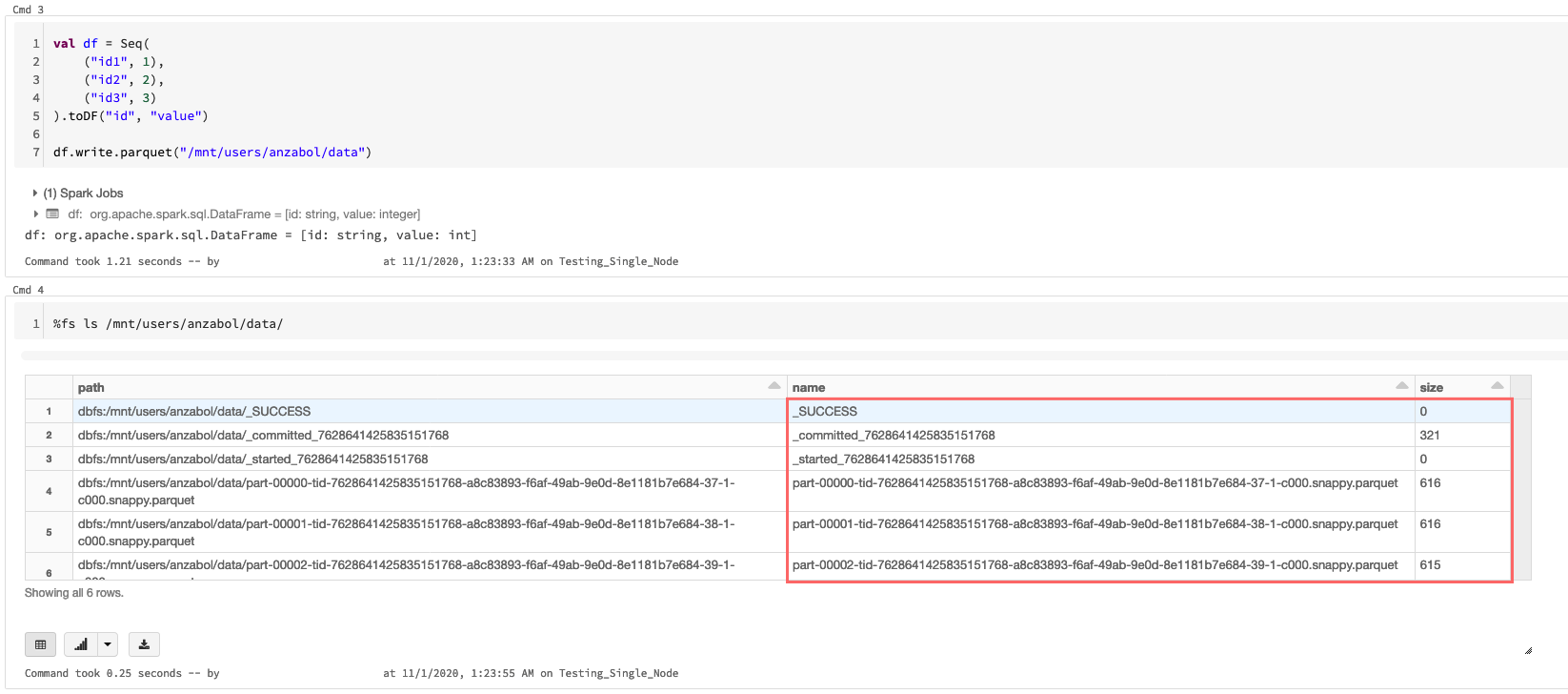
For each transaction, a unique transaction id <tid> is generated. At the start of each transaction, Spark creates an empty _started_<tid> file. If a transaction is successful, a _committed_<tid> file is created. Notice that each partition file also has the transaction identifier in it.
The content of the committed file for this transaction contains all the added partition files, as follows:
%fs head --maxBytes=10000 /mnt/users/anzabol/data/_committed_7628641425835151768
{
"added": [
"part-00000-tid-7628641425835151768-a8c83893-f6af-49ab-9e0d-8e1181b7e684-37-1-c000.snappy.parquet",
"part-00001-tid-7628641425835151768-a8c83893-f6af-49ab-9e0d-8e1181b7e684-38-1-c000.snappy.parquet",
"part-00002-tid-7628641425835151768-a8c83893-f6af-49ab-9e0d-8e1181b7e684-39-1-c000.snappy.parquet"
],
"removed": []
}
After writing another Dataframe to the same destination, with the append mode, the respective transaction files were created together with the partition files.
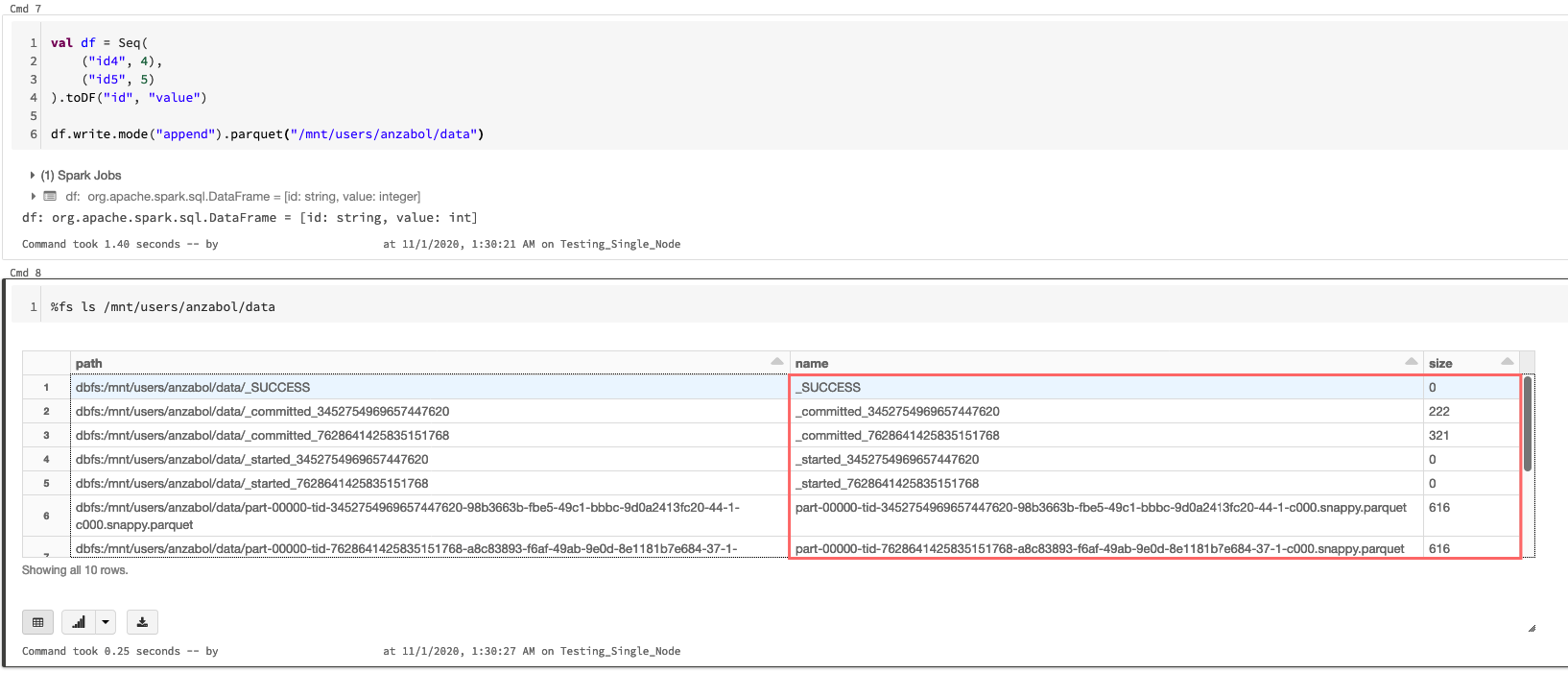
Once again, the committed file should contain all the files that were written during that transaction:
{
"added": [
"part-00000-tid-3452754969657447620-98b3663b-fbe5-49c1-bbbc-9d0a2413fc20-44-1-c000.snappy.parquet",
"part-00001-tid-3452754969657447620-98b3663b-fbe5-49c1-bbbc-9d0a2413fc20-45-1-c000.snappy.parquet"
],
"removed": []
}
My last test consisted in writing again the first Dataframe but with overwrite mode, to see what happens. In this case the committed file looked like this:
{
"added": [
"part-00000-tid-5097121921988240910-6ec8b872-eaca-4dd8-83b6-0822a8a18189-50-1-c000.snappy.parquet",
"part-00001-tid-5097121921988240910-6ec8b872-eaca-4dd8-83b6-0822a8a18189-51-1-c000.snappy.parquet",
"part-00002-tid-5097121921988240910-6ec8b872-eaca-4dd8-83b6-0822a8a18189-52-1-c000.snappy.parquet"
],
"removed": [
"_SUCCESS",
"part-00000-tid-3452754969657447620-98b3663b-fbe5-49c1-bbbc-9d0a2413fc20-44-1-c000.snappy.parquet",
"part-00000-tid-7628641425835151768-a8c83893-f6af-49ab-9e0d-8e1181b7e684-37-1-c000.snappy.parquet",
"part-00001-tid-3452754969657447620-98b3663b-fbe5-49c1-bbbc-9d0a2413fc20-45-1-c000.snappy.parquet",
"part-00001-tid-7628641425835151768-a8c83893-f6af-49ab-9e0d-8e1181b7e684-38-1-c000.snappy.parquet",
"part-00002-tid-7628641425835151768-a8c83893-f6af-49ab-9e0d-8e1181b7e684-39-1-c000.snappy.parquet"
]
}
As you can see, all the existing partition and success files were deleted, and the partition files of the written Dataframe added.
Since each successful transaction leaves a committed file, when reading data Spark ignores all the files that contain a <tid> for which there is no commit file. This way there is no way of reading corrupted / dirty data.
To clean up partition files of uncommitted transactions, there is VACUUM operation, that accepts an output path and the retention period.
Conclusion
Depending on your execution environment or expected behavior in case of application execution failure, different commit protocol should be chosen.
If your Spark application runs in Hadoop environment, you should use Spark’s Hadoop Commit protocol, that can be of version 1 or version 2. Version 1 is slower, but guarantees that no partial files will be left after a Spark Job is aborted. Version 2 is faster, but you will end up with partial results in destination directory when performing a write operation and it fails. One of these versions should be configured depending if safety or performance is your main concern.
If your Spark application runs in Databricks environment, you should definitely stick with their own commit protocol implementation called DBIO Transactional Commit, which is configured by default. This protocol offers at the same time safety (no partial/corrupt data) and performance, since it is optimized for cloud storage.
Resources
Apache Spark’s _SUCESS anatomy
What is the difference between mapreduce.fileoutputcommitter.algorithm.version=1 and 2
Transactional I:O on Cloud Storage in Databricks - Eric Liang
Transactional Writes to Cloud Storage on Databricks
Leave a comment